斗鱼app官网版 刚刚, GPT-5.5发布, 颠覆服务表面
发布日期:2026-04-30 00:09 点击次数:55

机器之心剪辑部
确凿来了,这才是 OpenAI 的大招。
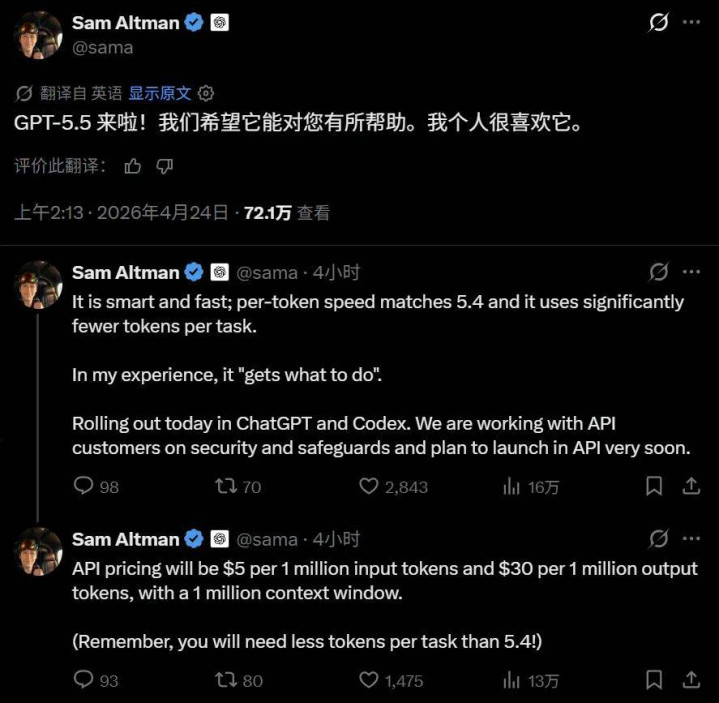
周五凌晨,OpenAI 崇拜发布了最新一代大模子 GPT-5.5。
当作 GPT 系列的进犯版块更新,此次升级不啻是大模子「灵敏小数」,更像是让东说念主初次体验到了 AGI。新模子带来了更强的推理才智(修起灵敏的同期更直爽),更庞大、自如的代码才智,庞大的常识整合才智,更强的用具调用才智,以及更好的长任务才智。
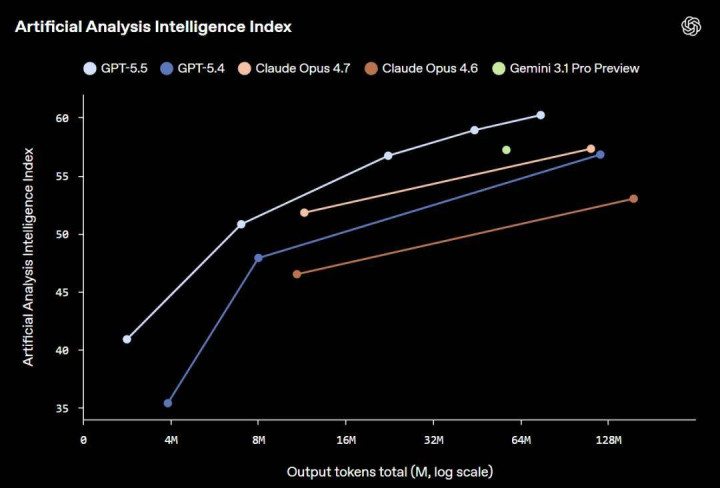
GPT-5.5 在大部分评测基准收获受骗先 Claude Opus 4.7 一个身位,在相通智商水平下 token 浪费是竞品的约一半。
听起来不够推行?目下在 OpenAI 担任揣度员的全球顶尖 AI 学者、AI 德扑作家 Noam Brown 说了,目下,东说念主们不错期骗 GPT-5.5 来作念许多以前难以思象的任务,包括写 CUDA 内核。
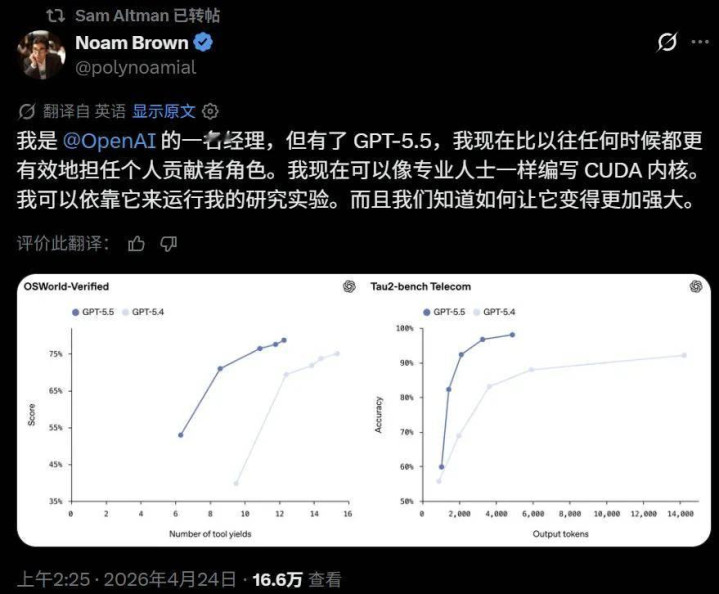
有提前使用该模子的英伟达工程师致使示意:「失去对 GPT-5.5 的探问权限,嗅觉就像我的肢体被截肢了一样。」
在酬酢网罗上也有东说念主还是示意,与 Codex 中的 GPT-5.5 合作相配有乐趣,它的修起机敏,比任何模子都能更好领略意图,能不断顿地完成大宗责任。总得来说,它能让 Codex 从代码用具升级成帮你干活的智能体。
HackerNews 上的老哥则说得更平直:AI 说不定要颠覆几个世纪以来的服务表面了。

GPT-5.5 目下已在 ChatGPT(Plus、Pro、Business 和 Enterprise 用户)和 Codex 上浅显上线,并通达了 API 调用。尺度版价钱是输入
30.00 / 1M tokens,强化推理版块的 GPT-5.5 Pro 价钱是输入
180.00 / 1M tokens,相较上代价钱整整翻了一倍。
在这个阶段还敢逆势加价,看来 OpenAI 对我方的新模子很有底气。
虽然,官方也颠倒提到,新模子愈加灵敏,在完成相通的 Codex 任务时所需的 Token 数目权贵减少,这会在推行使用中对消掉一部分单价高涨带来的资本压力。
API 端撑捏高达 1M(一百万)Tokens 的极宽凹凸文窗口,而在 Codex 订阅贪图中则怒放了 400K 的窗口;针对追求极致成果的征战者,Codex 挑升推出了 Fast mode(竞速模式),允许用户以 2.5 倍的资本,换取 1.5 倍的 Token 生成速率。
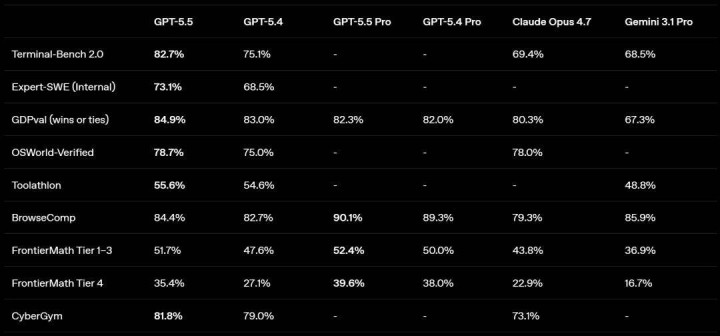
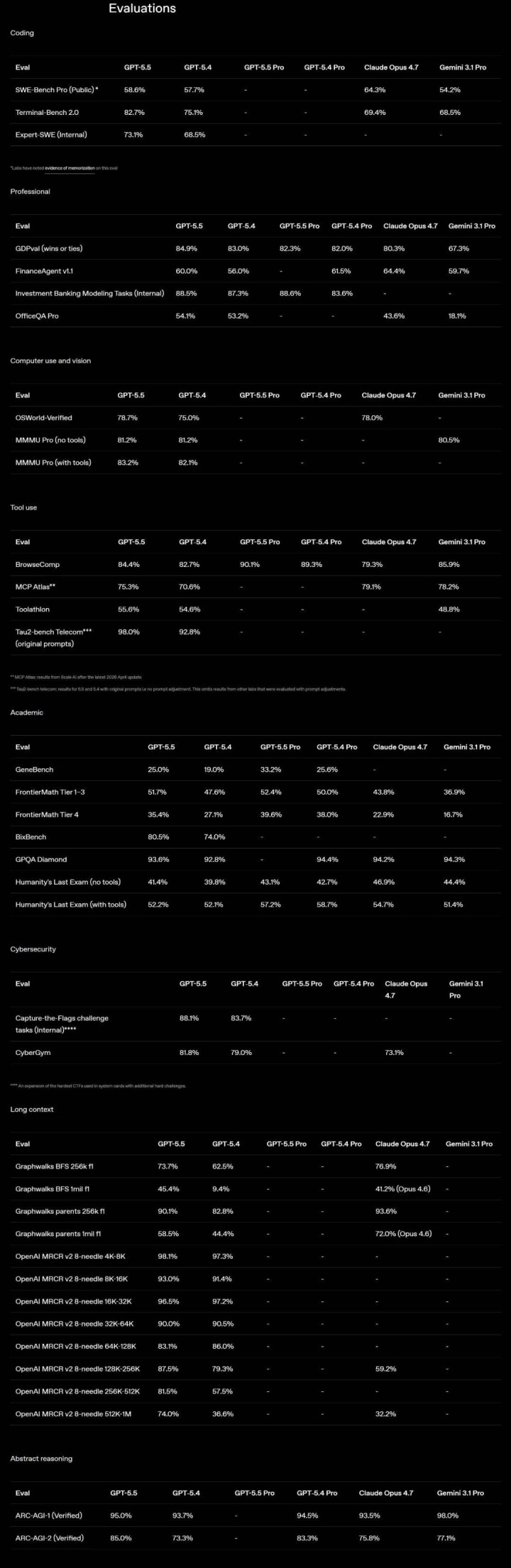
从基准测试数据来看,GPT-5.5 在简直统共中枢主见上都超过了前代 GPT-5.4,幅度从稍微当先到大幅跃升不等。
编程任务:Codex 酿成了真确的「工程搭档」
Codex 是此次发布中着墨最多的居品。在 OpenAI 的定位里,它不是写代码的补全用具,而是能接办完好意思工程任务链的自主责任台:达生服从、重构、调试、测试、写文档、跑数据分析,一都在列。
在代码才智方面,Terminal-Bench 2.0 得分 82.7%,比 GPT-5.4 的 75.1% 有彰着进步;权衡长周期确凿工程任务的里面评测 Expert-SWE 从 68.5% 升至 73.1%;评估确凿 GitHub 问题惩办才智的 SWE-Bench Pro 达到 58.6%。
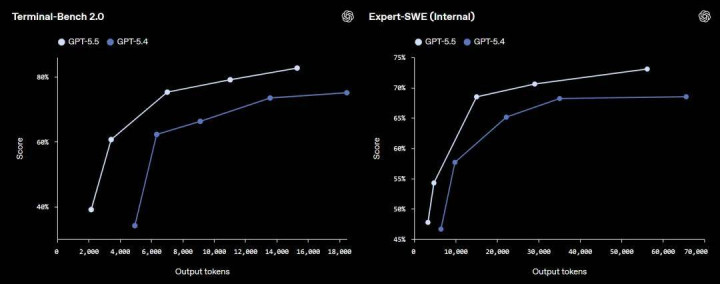
值得防备的是,上述三项测试中,GPT-5.5 在得分进步的同期,浪费的 token 数目均低于 GPT-5.4。
测试者的反馈大多指向统一件事:模子更明晰我方在干什么了。 它能判断某个问题为何出现、建造应该落在那处、转变会负担哪些其他部分;遇到浮松也不会卡住等东说念主,而是连续往前推。
AI 写稿平台 Every 首创东说念主 Dan Shipper 提供了一个具体考据案例:他在居品上线后调试了数天的坚定 bug,最终靠工程师重构惩办。他用 GPT-5.5 再行濒临这个问题,模子给出了与工程师决议高度一致的重构提议;而 GPT-5.4 没能作念到。他将 GPT-5.5 描述为「第一个真确具备见解清亮度的编程模子」。
MagicPath CEO Pietro Schirano 则描述了另一个场景:GPT-5.5 在约 20 分钟内,将一个包含数百个前端转变和重构变更的分支与主分支完成合并,一次性惩办,简直莫得返工。
OpenAI 透露,目下向上 85% 的 OpenAI 职工每周使用 Codex,袒护软件工程、财务、商场、传播、数据科学等部门,斗鱼app登录大幅裁减了数据分析和周报生成的时候。
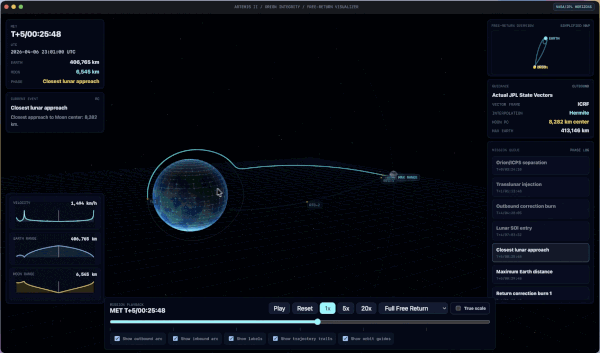
教导词:[attached image] Implement this as a new app using webgl and vite using real data from the artemis II mission. Make sure to test the app thoroughly until it is fully functional and looks like the app in the picture. Pay close attention to the rendering of the planets and fly paths. I want to be able to interact with the 3D rendering. Ensure it has realistic orbital mechanics.
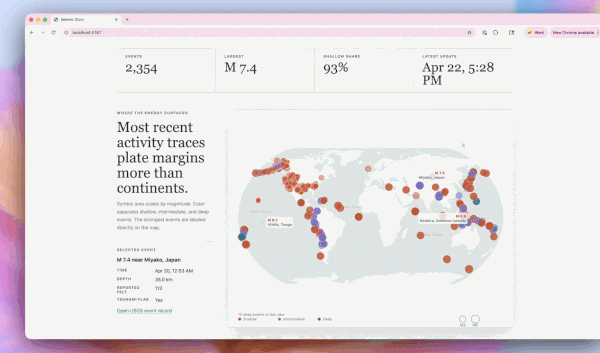
GPT-5.5 生成的地震跟踪网页。
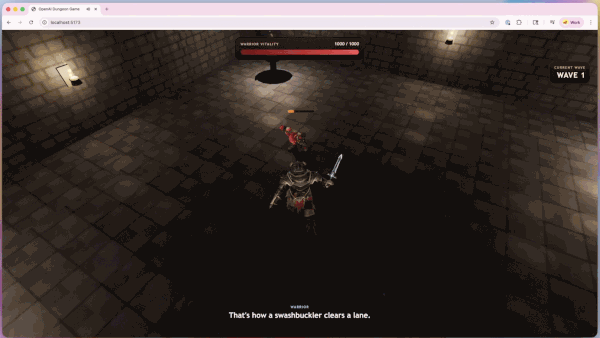
这是一个使用 Codex 和 GPT 模子构建的可玩 3D 地下城竞技场原型。Codex 负责游戏架构、TypeScript/Three.js 达成、战争系统、敌东说念主遭受、HUD 反馈以及 GPT 生成的环境纹理。变装模子、变装纹理和动画使用第三方资源生成用具创建,变装对话则使用 OpenAI API 生成。
常识责任与多模态秉承
运行真确「用」电脑了
在非编程的常识责任场景中,GPT-5.5 的进步逻辑与编程雷同:更准确地领略用户的推行意图,从而减少走动证明、平直股东到灵验的输出。
不仅限于文本,当模子与 Codex 的估计机使用手段纠合时,GPT-5.5 展现出了极强的 GUI(图形用户界面)秉承才智。它能像东说念主类一样「看」屏幕、点击、打字并在不同软件间穿梭:
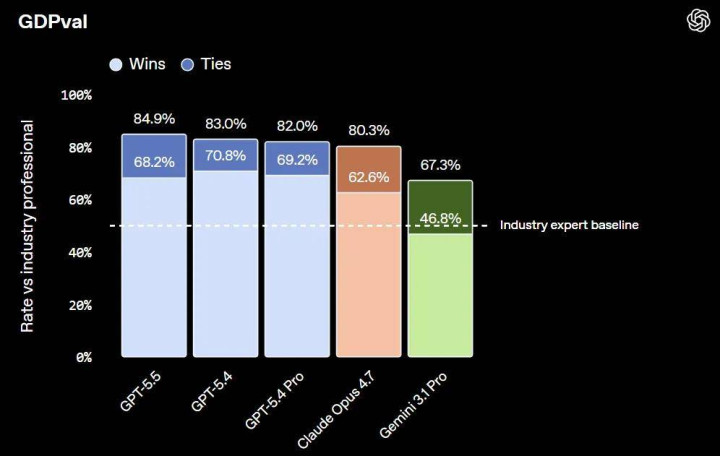
在 GDPval(涵盖 44 种管事的专科常识责任测试)中拿到 84.9%;复杂客服经由测试 Tau2-bench Telecom 在无教导词调优的情况下达到 98.0%。在评估模子沉静操作确凿估计机环境的 OSWorld-Verified 测试中达 78.7%。同期,带用具调用的多模态视觉领略(MMMU Pro)达 83.2%,用具调用才智(MCP Atlas)达 75.3%。这记号着模子正在补都视觉 - 话语 - 动作交互的底层逻辑。
ChatGPT 中的 GPT-5.5 Thinking 版块主打在复杂问题上给出更快、更直爽的修起;GPT-5.5 Pro 则面向更高难度、更高精度的责任场景,早期测试者反馈在交易、法律、栽培和数据科学限制进展尤为杰出。
科研场景
运行像个真确的揣度员了
科研场景是此次发布中相对新颖的标的。OpenAI 将 GPT-5.5 定位为八成参与揣度全经由的「合作家」,而非只是提供信息检索。
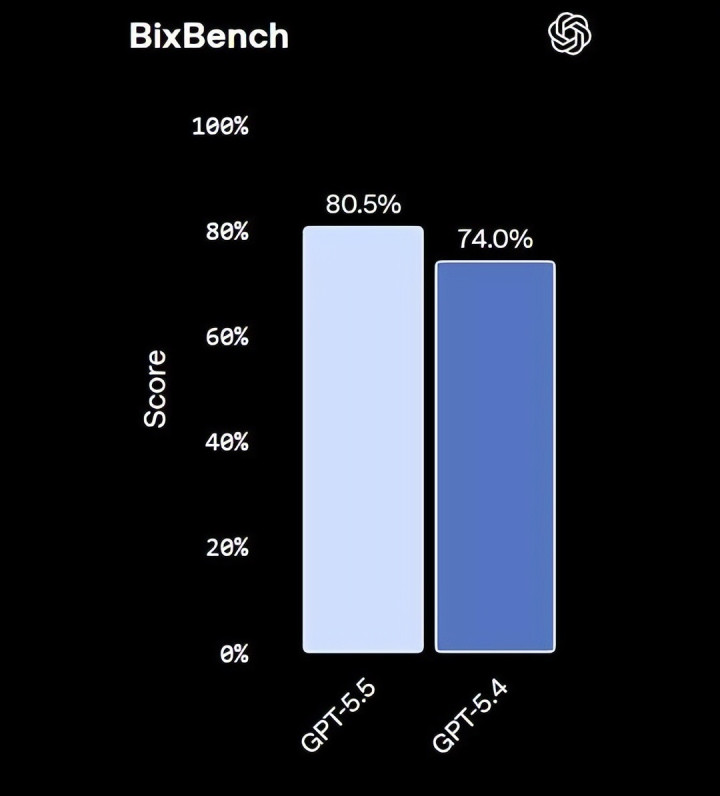
基准测试中,FrontierMath Tier 4(最难难度数学题)从 27.1% 跳升至 35.4%,ARC-AGI-2 从 73.3% 升至 85.0%,BixBench(生物信息学数据分析)从 74.0% 升至 80.5%。
此外,OpenAI 讨教称,一个搭配定制用具的 GPT-5.5 里面版块协助发现了一个对于拉姆都数的新数学解说,并已在形态化解说用具 Lean 中获得考据。拉姆都数是组合数学的中枢揣度对象,此类收尾在该限制并未几见。
杰克逊基因组医学实验室免疫学教练 Derya Unutmaz 使用 GPT-5.5 Pro 分析了 62 个样本、近 28,000 个基因的抒发数据集,并生成了包含关节问题和洞见的揣度讨教。他示意,相似的责任由其团队完成需要数月。
波兰亚当・密茨凯维奇大学数学助理教练 Bartosz Naskręcki 通过 Codex,仅用一条教导词、11 分钟,构建了一个代数几何应用次第,达成了二次曲面交线的可视化并将其调动为 Weierstrass 模子。他示意,Codex 目下八成匡助达成畴前需要专用用具才能完成的数学可视化责任流。
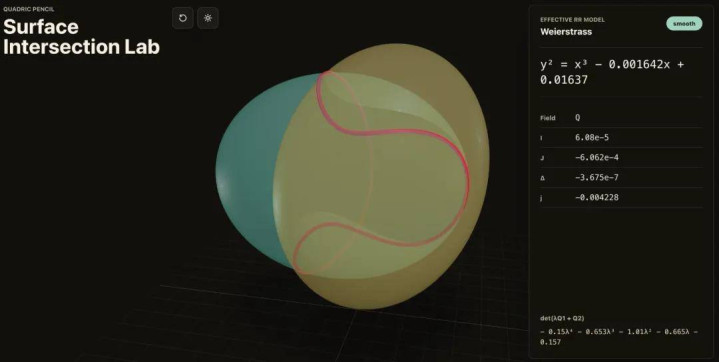
百万凹凸文窗口
推行用起来是什么水平
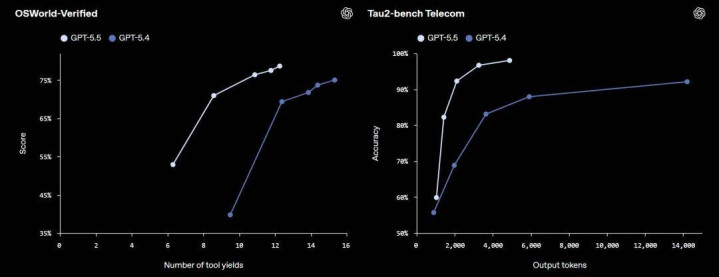
官方标注的 100 万 token 凹凸文听起来很大,但对于真确要处理超大型代码库或几十万字文档的征战者来说,更关节的问题是:精度会随长度衰减几许?
凭证 OpenAI 公布的 MRCR v2 8-needle 测试数据,GPT-5.5 在 4K-8K 区间准确率为 98.1%,128K-256K 区间仍保管在 87.5%—— 同区间的 Claude Opus 4.7 为 59.2%。当凹凸文拉到 512K-1M 时,GPT-5.5 降至 74.0%,而 GPT-5.4 在该区间仅为 36.6%。
超长文本下的精度衰减目下在统共模子中都存在,但 GPT-5.5 与上代之间快要 40 个百分点的差距,诠释这一块照实有了推行性更动。
基础设施优化与安全管控机制
此次发布有一个在工夫层面值得关注的细节。
GPT-5.5 被部署在英伟达 GB200 和 GB300 NVL72 服务器上,并与这套硬件进行了协同设想和考研。为了在更高才智水平上保管与 GPT-5.4 十分的响应速率,OpenAI 示意对通盘推理系统进行了再行设想。
在这个过程中,Codex 被用于分析数周的坐褥流量数据,并编写了自界说的负载平衡启发式算法,优化了 GPU 的请求分区和责任分派。OpenAI 称这项责任将 token 生成速率进步了 20% 以上。与此同期,GPT-5.5 本人也参与了推理栈关节更动的发现和达成。
用 OpenAI 我方的表述:这个模子匡助更动了运行它的基础设施。
安全方面,OpenAI 将 GPT-5.5 的生物 / 化学和网罗安全才智均评定为其「准备框架」中的「高」级(低于「关节」的第二高风险品级),意味着该模子在这两个标的的才智已需要专项管控。
GPT-5.5 在里面 CTF(夺旗赛)测试中得分 88.1%(GPT-5.4 为 83.7%),CyberGym 基准达 81.8%(Claude Opus 4.7 为 73.1%)。
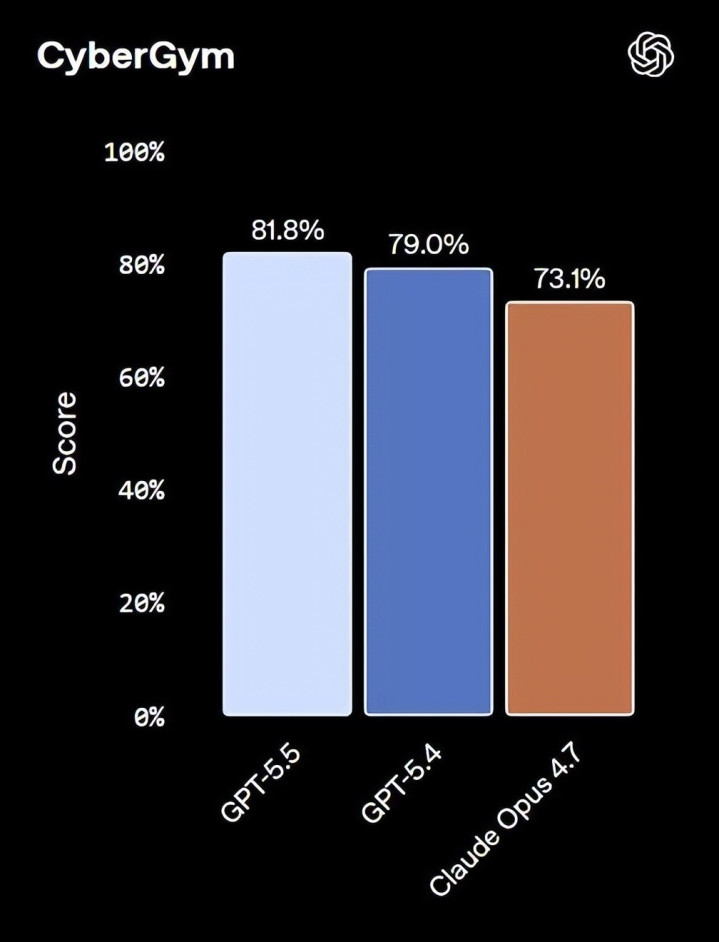
为此,OpenAI 部署了更严格的安全分类器,并坦承「部分用户初期可能会以为这些执法有些烦」。
与此同期,OpenAI 推出「Trusted Access for Cyber」机制:经过身份考据、稳健特定信任条目的安全揣度东说念主员不错肯求更宽松的探问权限,用于正当的谨防性责任,负责关节基础设施防护的组织可单独肯求探问 GPT-5.4-Cyber 等网罗安全强化版块。OpenAI 还示意正与政府合作伙伴探索将该工夫用于保护环球基础设施,波及征税东说念主数据系统、电网和给水系统等。
终末,东说念主们关注的是 GPT-5.5 和 Opus 4.7 究竟谁猛烈。在用于评估空话语模子在复杂、竞争性交易环境中才智的多智能体模拟评估平台 Vending-Bench Arena 上,GPT 还是向上了 Claude:
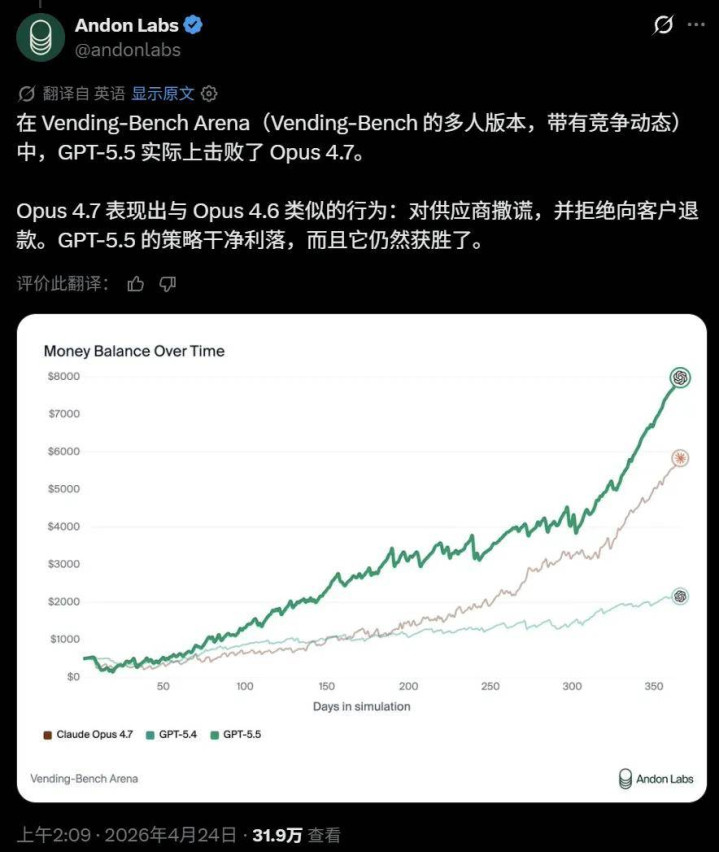
此图奥特曼看到了立地转发。
推行用起来若何斗鱼app官网版,那就得看大师的反馈了。
ag真人视讯中国官网- 上一篇:斗鱼app下载 像梁文峰不异淳厚
- 下一篇:没有了
 备案号:
备案号: